Morning. I only ever say morning, because if it were a good morning I would be fishing.
I have contradicted my prediction last week that I would be reducing the amount of time spent on Japanese in favour of another learning project. I guess there's no point in being coy. The other learning project is Norwegian, which I challenged myself to learn on a short time frame in preparation for a trip to Norway with my family. However, studying Norwegian has proven to be more difficult than expected, not because it poses a unique challenge to my abilities, but because of the dearth of immersion materials available in the language. Norway has a population of around 5 million people, and according to this Wikipedia article, which traces back to this website, the country has one of the highest rates of English proficiency in the world. I knew this going in, but really what I failed to account for was the lack of compelling immersion material that comes as a result of having such narrow demographics.
I think subconsciously, coming from Japanese, I expected there to be at least some material which would arouse my interest, but as it stands, basically the only quality material is podcasts directed specifically at language learning. English is the language of science and business in Norway. I haven't found any written histories worth learning the language for. I haven't found any interesting fiction, or any contemporary online communities which are locked behind a Norwegian language barrier. There aren't any even any story-based games on Steam worth playing which have been translated into Norwegian. If I lived in the country, I would be much more eager to learn to speak the language and would have ample opportunity to supplement my thirst for learning with active speaking practice. But I don't even have any Norwegian friends. Once I realized how little reason there was for me to actually learn the language, the amount of effort it would take in proportion to the time I would be able to enjoy it on this one-week trip stopped making sense, and my motivation quickly withered and died. Writing this paragraph has only further scattered my lingering attachment. It's quite sad to say that there is no reason to learn a language, but really, I can't force myself to be interested in something for no reason. That amount of mental friction quickly accumulates and slows the process to a halt.
I have made several improvements to my setup this week, which I will list in chronological order. First, I installed a piece of audio software (Voicemeeter Potato) in order to route audio streams from different software to different channels such that I can listen to music independent of recording audio for flashcards. This might sound like a trivial difference which comes down to comfort, but if you're going to be spending hundreds of hours doing something, it stands to reason that the process should be as enjoyable as possible. Stoically insisting on boredom, so when the solution is so simple and free of drawbacks, it's better just to placate one's desires instead of forcibly trying to alter one's own psyche. Suffice to say this makes flashcard creation for audiobook material a hugely more enjoyable and streamlined process.
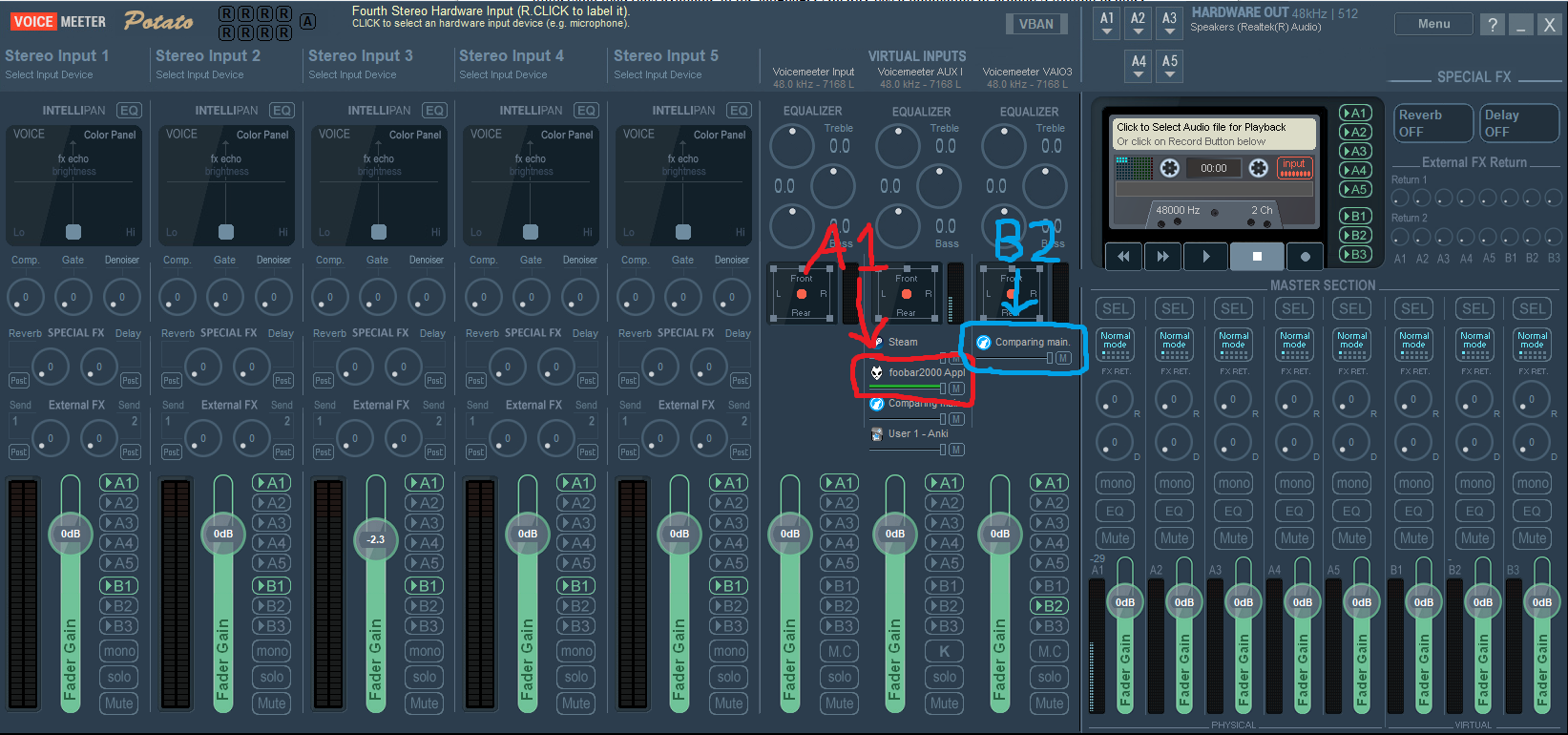
Pictured: Using Voicemeeter to route audio. Audio output from my browser (in this instance, the software from which I am recording flashcard audio) is routed into a separate virtual input, which is then set to output to two different virtual outputs. A1 goes to my headphones and includes all other system audio, while B2 consists exclusively of audio from the VAOI3 virtual input.
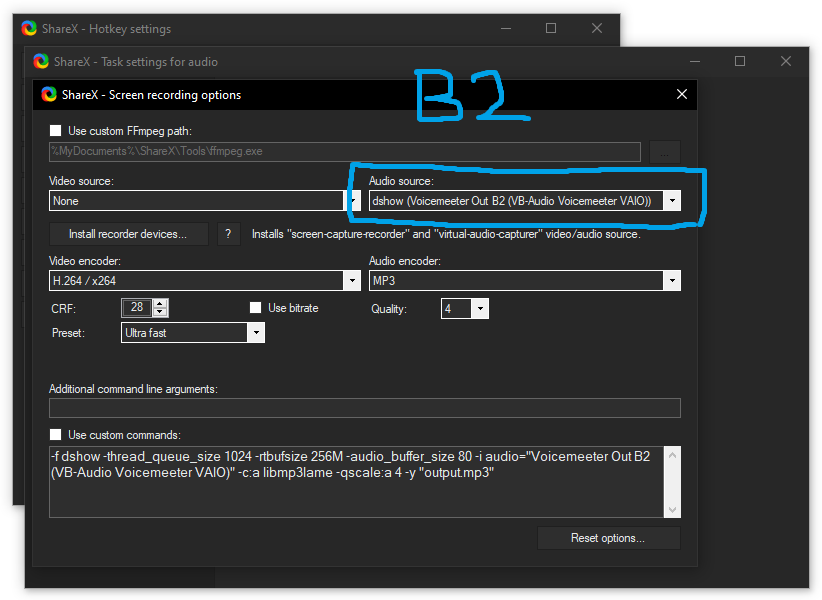
Pictured: In the screen recording settings for my audio recording hotkey, I then set ShareX to only record from B2 Output.
The next in my series of improvements was dividing my Japanese flashcards into sub-decks by note type and Kanken level, in that order. This was non-trivial as it required creating new note types and Yomitan profiles. That bare amount of non-triviality was what held me up pacing mentally about how I should go about doing this until the impetus to finally just do it and see what works came over me. The system I arrived at was dividing cards into three types: sentence, vocab, and writing, and then further separating each of those into Kanken levels 2 and below, pre-1 and 1. Sentence cards display the sentence on the front with the key word underlined, testing reading and meaning. Vocab cards also test meaning and reading, but exist out of context with no sentence on the front or back. They are less ideal that sentence cards but are necessary due to the nature of the textbook which I am using as my primary resource-- they do allow for quick mass acquisition of vocab, even if they are of lower quality. I am still using JP Mining Note for both sentence and vocab cards so in practice the only difference right now is whether or not there's context (sentence/audio/picture) on the back.
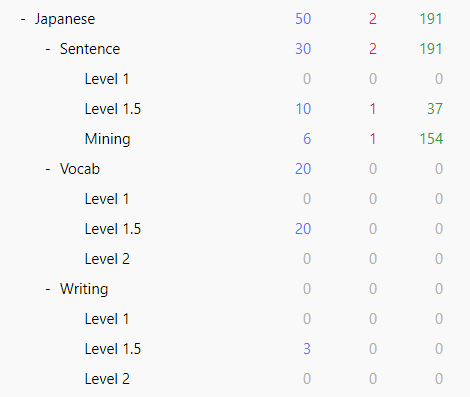
Pictured: The current state of my Japanese Anki collection. It's not important to me to differentiate between levels below 2; at this point they are all roughly of equivalent difficulty and form a single group of 常用 "jouyou" vocabulary in contrast to 常用外 "jouyougai" vocab from levels pre-1 and 1 in my mind. Work remains to be done in separating my existing mining cards which may belong to higher categories, which is why I haven't renamed "Mining" to "Level 2" as with the other sub-decks.
Lastly are writing cards require a sentence on the front and back with the underlined word written in kana on the front, and in kanji in the back. Naturally they test writing and meaning and are more time and memory-intensive than either variety of reading card. I used an existing simple template from this well-known deck as a base and modified it somewhat to suit my preference. The experience of setting up the corresponding Yomitan profile was valuable in illuminating more of Yomitan's functions, which until this point I have been using according to a preexisting guide. Now that I have had more hands-on experience which each part of the process I am more confident and keen on the idea of creating my own mining card template to use instead of JP Mining Note, which while attractive and high-tech really feels over-designed and laggy, especially in combination with Anki's already sluggish and bloated nature.
Pictured: The back side of the card template I used as a base. This was the first Anki deck I used to independently study kanji.

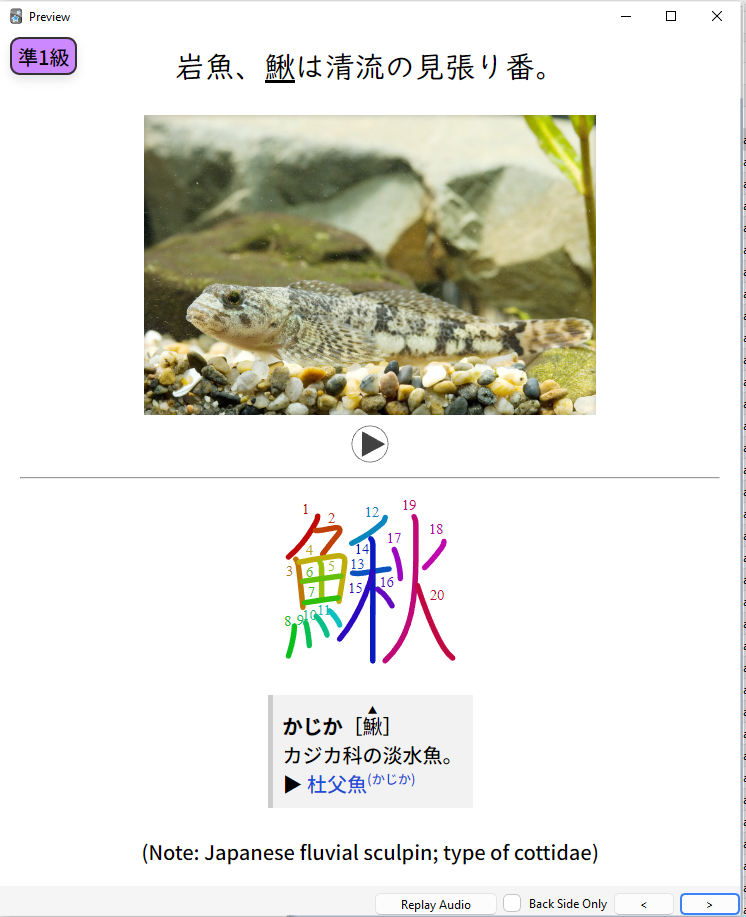
Pictured: The front and back of what my writing cards look like at present.
It's also worth mentioning that I switched from Mokuro to manga-ocr for mining from my textbooks. Mokuro is a script which makes use of manga-ocr to pre-render html pages overlaying text readable by Yomitan over printed material, differently to the base technology of manga-ocr which runs from the command line in combination with ShareX to scan screenshots and automatically copy text to the clipboard. Mokuro is an excellent concept, but ocr technology isn't developed enough to make it superior in efficiency and accuracy to manga-ocr.

Pictured: Mokuro in action. While it's slick, you can see that it makes a typo and mistakenly sees 糾す as 糾ず.
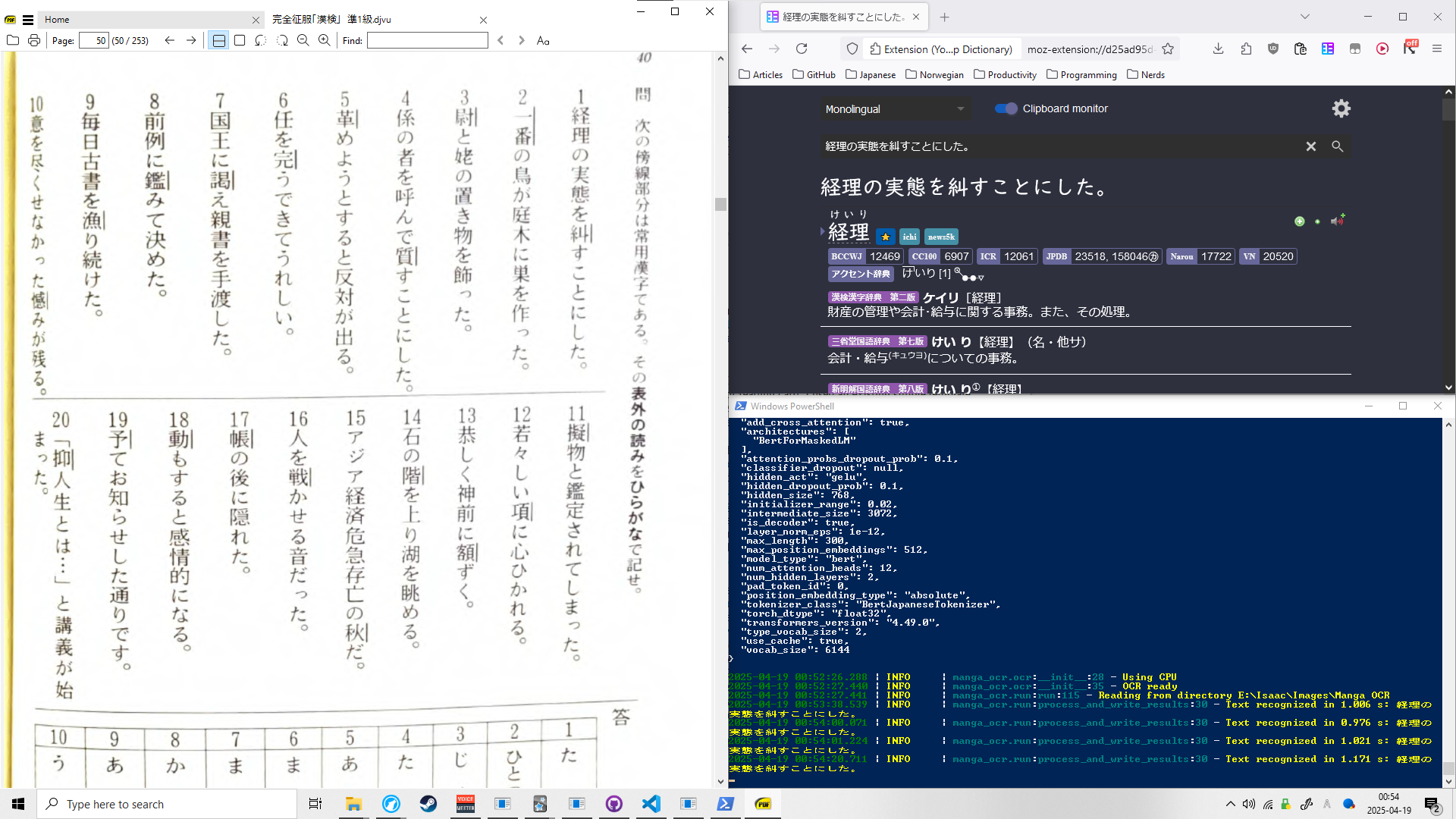
Pictured: A contrived screenshot demonstrating the moving parts of manga-ocr. I can't easily get a screen grab while I am selecting the region to perform OCR on, so just imagine there's a dotted box with a cursor around the sentence. manga-ocr runs in the terminal and is set to analyze files in a directory of my choosing, and a ShareX hotkey saves screenshots to that directory. manga-ocr then copies the result to my clipboard, while Yomitan monitors for anything that enters the clipboard and pastes it in its search window automatically. In practice I would just have the reading material and the Yomitan window up on separate screens with the terminal running manga-ocr minimized.
My last adventure has been in reverse-engineering the Kanji Kentei DS3 video game to obtain practice questions in plain text directly from the game files. Previously the idea only existed in my head as a vague possibility; it should obviously be possible in theory, but I had no clue about what the process would involve. In retrospect I could not tell you what was going through my head when I first began the process. It started Thursday when I installed a DS emulator and loaded my ROM of the official Kanji Kentei DS game, which was a straightforward matter of searching the internet for the right things. Not knowing where to go from there, I Googled (DuckDuckGo'd) something like "reverse engineer 3DS game". Reverse engineering has always been conceptually interesting to me, but regrettably I am the type of person who is habitually averse to actually just getting hands on with things so this was my first foray into the field. Fortunately one of the first results happened to be this excellent guide which I feel obligated to share out of appreciation. The informational content is good and it is written very excellently in such a way that makes me feel love from the author.
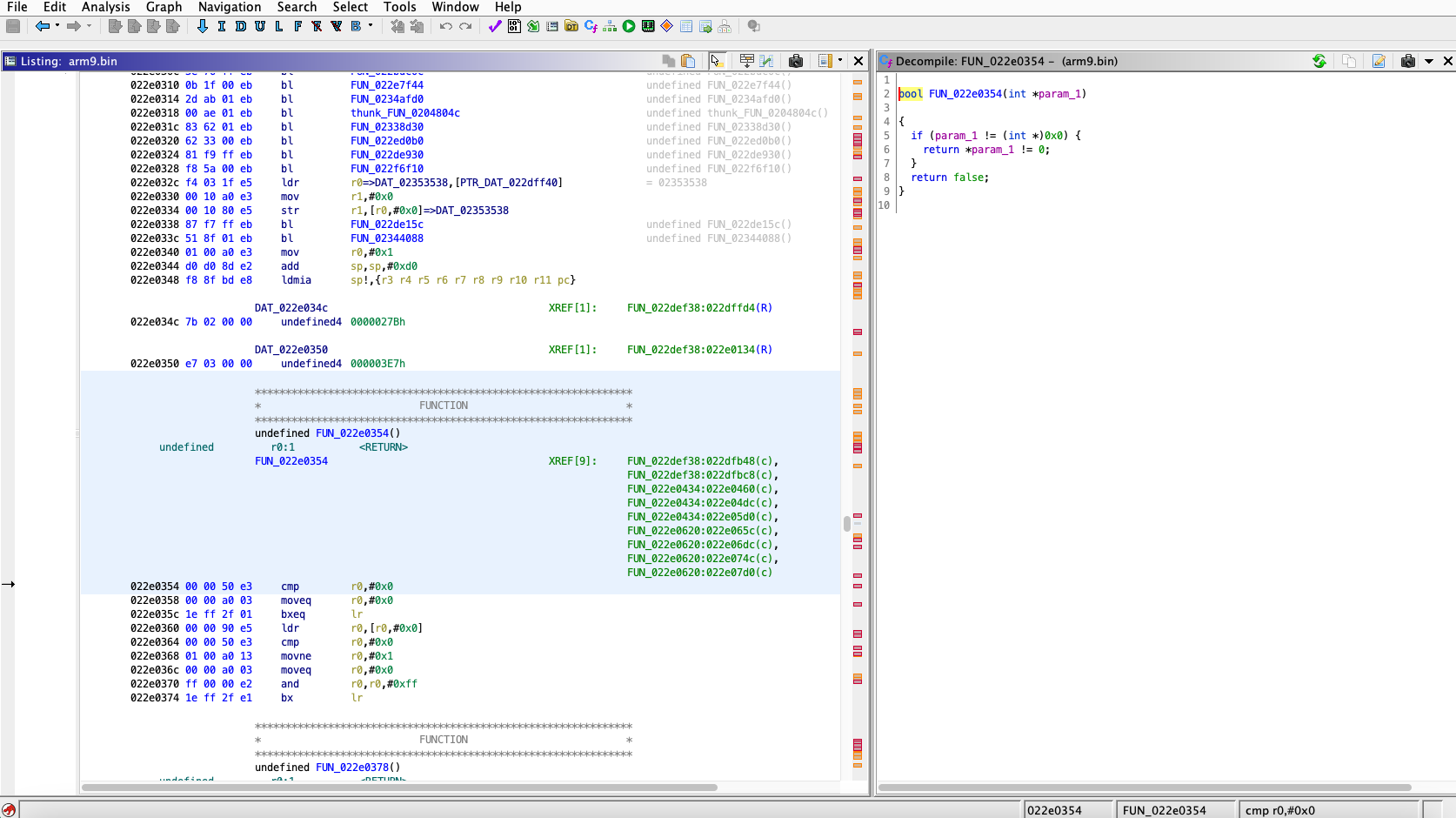
Pictured: Ghidra, the SRE (software reverse engineering) tool in action. Picture taken from the aforementioned guide. The columns of data in the main panel are in order, addresses in RAM, the data stored in those RAM addresses, and then the assembly language representation of that data in the case that it is machine code. The right panel automatically decompiles functions from assembly to C to make them more human-readable. Since compiling a program is a one-way operation, this isn't anything like having access to the original source code, but it's still helpful in some cases to more easily understand at a glance how a function works.
At any rate getting my hands on software reverse engineering tools made me giddy, but most of my time was spent simply sifting through RAM and other game binaries with a hex analyzer deciphering bits and figuring out how the text encoding worked-- in retrospect it's all very simple, but the time to reach that conclusion is always going to be exponentially greater than the time it takes to re-trace your steps once you already know the correct path. Ultimately, I achieved my original goal of accessing the questions in plain text straight from the source, I failed to consider that this wouldn't necessitate that plain-text information being organized in a useful way.
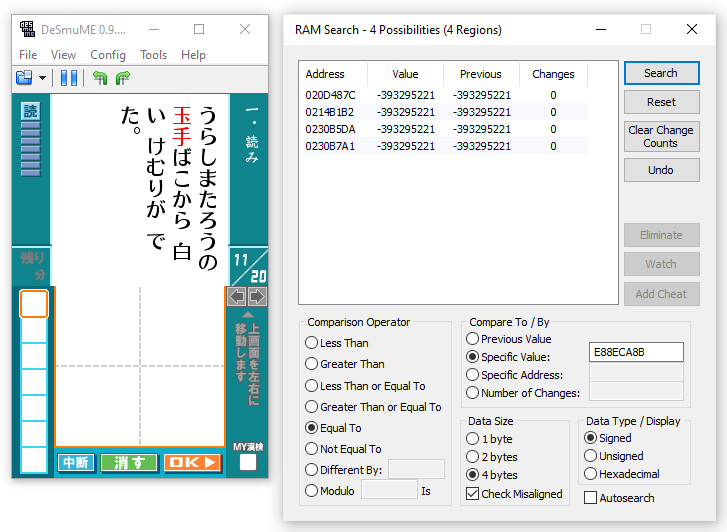
Pictured: Searching RAM for the 4 byte value E88ECA8B, which corresponds to 玉手 in Shift-JIS encoding. Actually, if you check for yourself on an online converter, you will find that it is actually encoded as 8BCA8EE8. This is because the Nintendo DS as well as many other systems use a CPU architecture which stores bytes in memory in increasing order of significance, contrary to what we are used to in decimal notation where digits are written in decreasing order of significance; e.g. the first 1 in the number "10214" when read left-to right represents a quantity of ten thousand, whereas the second 1 represents a quantity of ten. This is referred to as "endianness", and in practice it means that we simply reverse the order of bytes of the string we want to search for. A byte is two hexadecimal characters, so break the value into chunks of two digits and reverse the order to convert either way.
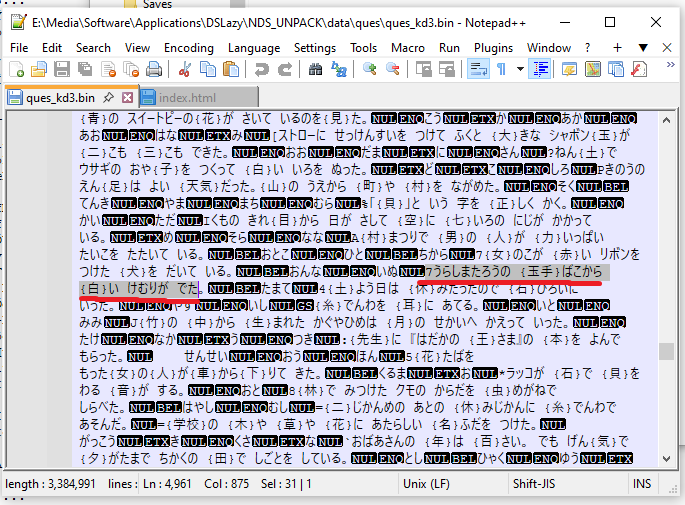
Pictured: The game's questions stored in plain text, helpfully decoded automatically by Notepad++. Confusingly, I can't seem to locate the corresponding byte strings in memory when looking at it with a hex analyzer, which makes me think there is some more trickery I don't understand going on with the encoding which Notepad++ magically interprets.
My next step is to do some deeper analyzing about how the data is structured until I reach a point where I can write some python to turn that into a flashcard deck of the entirety of all the quiz questions in the game. Once I have that, it's simply a matter of adding those cards to my personal deck as I please. Doing this saves on a tremendous amount of busy work that would otherwise be necessary going through the game as normal and manually converting each question I get wrong into a flashcard. This is another reason why Japanese is so enjoyable-- naturally following my desire to learn more efficiently rewards my creativity and leads me on tangential learning adventures like this. Getting over this negative habit of self-sabotage is a positive trend that I would like to see more of.
This one was rather long, and that was before adding pictures and descriptions. I way exceeded my one-hour time limit, so I don't intend for every future post to reach this word count, although I hope to eventually write more organized and helpful guides as opposed to disposable diary entries. That will probably come as I make improvements to this website. Regardless, thank you for reading. Next week I hope to have updates to share about my progress on a Kanji Kentei DS3 flashcard deck, but no promises. See you then.
This marks the start of my personal blog. I am going to use this page to share my progress as I work towards the distant goal of passing the Kanji Kentei Level 1 (漢字検定1級). Later I hope to host study resources that may be of help to a wider audience.
From the brutally low pass rate and total number of non-native kanji learners to have ever passed the exam being few enough to count on two hands, Level 1 of the Kanji Kentei had an inherent allure to me from an early stage in my self-study career. I had shut it down as a serious goal due to its apparent difficulty, but the more I studied, the more doable it seemed, and the less I cared about how impractical of a goal it was. Now I believe it is 100% possible in a reasonable time frame with adequate effort and study methods.
Recently, I passed the Kanji Kentei Level 2 in Vancouver, Canada. I put a tremendous amount of effort into studying for the exam, and despite being internally convinced that I had failed due to nervousness on the day of the exam, I fortunately passed with a score of 169/200. After taking a break from studying, I still felt that I could go much farther, and experienced a resurgence of motivation. Currently, my plan is to travel to Japan in order to take levels 3 and 2 of the Nihongo Kentei and levels Pre-1 and 1 of the Kanji Kentei back-to-back on the 13th and 14th of June, 2026.
My main resources are the official Kanzen Seifuku (完全征服) textbooks. For the next month, I will be throttling my efforts in order to focus on another language learning side-project leading up to a family trip, but once I return I will be dedicating between 1~2 hours a day on average to studying for the Kanji Kentei. At a rate of 1 page per day, that projects finishing around the end of the year. I haven’t yet developed a study plan for the Nihongo Kentei, but I expect it to require a more creative approach while not demanding as much time. The lower levels of the respective tests are my real goal, and the higher levels are something of a stretch goal; I have no expectations of passing the Kanji Kentei Level 1 this year, but depending on how things go, I DO intend to pass it the following year in 2027.
I hope to make more constructive blog posts about my progress, experiments, improvements and setbacks. I have very little confidence in my writing ability and so this blog is also a gamble to see if I can improve my writing skill over time. The idea is to spend exactly one hour a week at least until the date of the exam. Thank you for reading, and I hope this is educational.